What are Transformers in AI/ML?
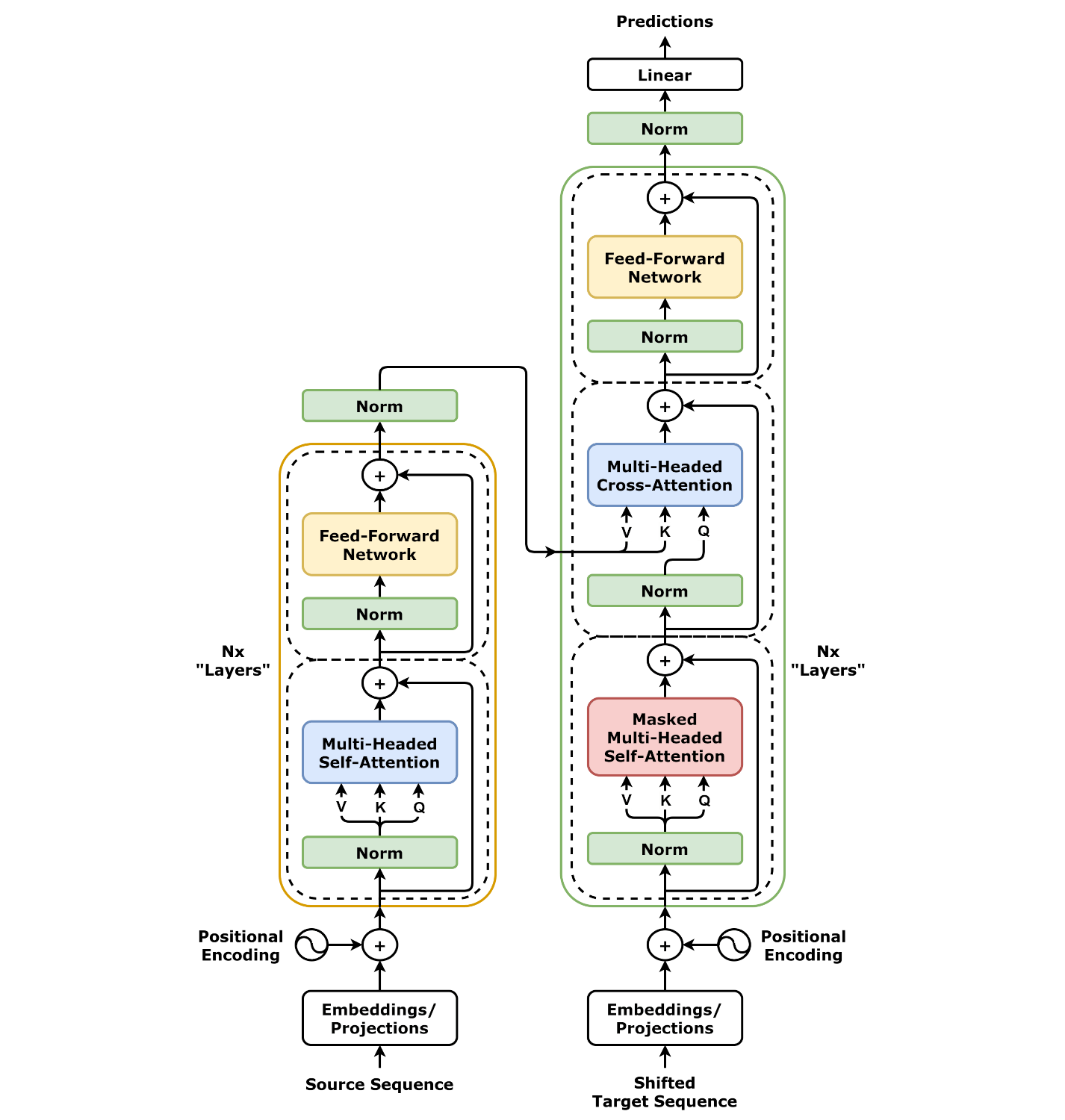
Transformers are a type of architecture in artificial intelligence (AI) and machine learning (ML) that has had a significant impact on various natural language processing (NLP) tasks and other sequence-to-sequence tasks. They were introduced in a 2017 paper titled "Attention Is All You Need" by Vaswani et al. and have since become a fundamental building block for many state-of-the-art models in NLP and beyond.
Here are key aspects of transformers in AI and ML:
- Attention Mechanism: Transformers are built around an attention mechanism, which allows the model to weigh the importance of different parts of the input data when making predictions. This attention mechanism enables transformers to capture complex relationships and dependencies in the data, making them highly effective for sequential data, such as text or time series.
- Parallelization: Unlike recurrent neural networks (RNNs), which process data sequentially, transformers can process input sequences in parallel, making them computationally efficient and suitable for GPU acceleration.
- Self-Attention: Transformers use self-attention mechanisms to weigh the importance of different elements within a sequence. This self-attention allows the model to consider context from all positions in the input sequence simultaneously, making it well-suited for tasks requiring a deep understanding of context.
- Encoder-Decoder Architecture: Transformers typically consist of an encoder and a decoder. The encoder processes the input data, while the decoder generates the output. This architecture is particularly useful for sequence-to-sequence tasks like machine translation, text summarization, and language generation.
- Positional Encoding: Since transformers do not inherently possess knowledge of the order or position of elements in a sequence (unlike RNNs and LSTMs), positional encoding is added to the input data to give the model information about the positions of elements in the sequence.
- Multi-Head Attention: Transformers often use multi-head attention mechanisms, which allow the model to focus on different parts of the input data in parallel and learn different aspects of the data. This improves the model's ability to capture different types of relationships within the data.
- Pretrained Models: Pretrained transformer-based models, such as BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pretrained Transformer), have achieved remarkable results in various NLP tasks. These models are pre-trained on large text corpora and fine-tuned for specific downstream tasks, offering a transferable and efficient way to tackle a wide range of NLP challenges.
- Transfer Learning: Transformers have popularized the concept of transfer learning in NLP. Models pre-trained on vast amounts of data can be fine-tuned on smaller, task-specific datasets, reducing the need for extensive labeled data for each new task.
Transformers have revolutionized the field of NLP and have been extended to various other domains, including computer vision (with models like Vision Transformers or ViTs) and reinforcement learning.
What are Transformer Types in AI/ML?
There are two main types of transformers in artificial intelligence (AI) and machine learning (ML):
- Encoder-decoder transformers: These are the most common type of transformer and are used for a variety of tasks, such as machine translation, text summarization, and question answering. Encoder-decoder transformers consist of two parts: an encoder and a decoder. The encoder takes an input sequence and converts it into a hidden representation. The decoder then takes the hidden representation from the encoder and generates an output sequence.
- Autoregressive transformers: These are used for tasks such as text generation and code generation. Autoregressive transformers generate output sequences one token at a time. They do this by using a decoder that predicts the next token in the sequence based on the previous tokens.
In addition to these two main types, there are also a number of other transformer types that have been developed for specific tasks and designed for specific applications.
- BERT (Bidirectional Encoder Representations from Transformers): BERT is a transformer model developed by Google that revolutionized NLP. It is pre-trained on a large corpora of text and can be fine-tuned for various downstream NLP tasks such as text classification, named entity recognition, and question-answering. BERT captures bidirectional context, allowing it to understand the meaning of words in a sentence.
- GPT (Generative Pretrained Transformer): The GPT series, developed by OpenAI, includes models like GPT-2 and GPT-3. These models are designed for text generation tasks and have shown remarkable performance in tasks such as language generation, text completion, and chatbot development. GPT-3, in particular, is known for its large scale and versatility.
- Google Bard: Google Bard is a large language model (LLM) chatbot developed by Google AI, based on the LaMDA family of LLMs and later the PaLM LLM. Bard is trained on a massive dataset of text and code, and it is able to communicate and generate human-like text in response to a wide range of prompts and questions. It can answer questions, translate languages and generate different creative text formats of text content, like poems, code, scripts, musical pieces, email, letters, etc.
- T5 (Text-to-Text Transfer Transformer): T5, developed by Google, is a transformer model that frames all NLP tasks as a text-to-text problem. It has achieved state-of-the-art results on a wide range of NLP benchmarks and can be fine-tuned for various NLP tasks by simply providing input and output text pairs.
- XLNet: XLNet is a transformer model that extends the autoregressive language modeling approach of GPT with a permutation-based training technique. It considers all possible permutations of the input data, improving its ability to capture complex relationships in text.
- RoBERTa (A Robustly Optimized BERT Pretraining Approach): RoBERTa is a variant of BERT that optimizes the pretraining process by using more data and larger batch sizes. It has shown improved performance on various NLP tasks and is known for its robustness.
- ALBERT (A Lite BERT): ALBERT is designed to reduce the number of parameters in BERT-style models while maintaining or even improving their performance. It uses parameter sharing techniques to achieve efficiency while retaining effectiveness.
- DistilBERT: DistilBERT is a distilled version of BERT that aims to reduce the model's size and computational complexity while preserving much of its performance. It's designed for tasks with resource constraints.
- ERNIE (Enhanced Representation through kNowledge Integration and External-memory): ERNIE, developed by Baidu, extends transformer models by integrating external knowledge sources and leveraging them for better understanding and reasoning in text.
- ViT (Vision Transformer): ViT applies the transformer architecture to computer vision tasks. It has shown promising results in image classification, object detection, and other vision-related tasks.
- BART (Bidirectional and Auto-Regressive Transformers): BART is a transformer-based model designed for text generation tasks. It can be used for tasks such as text summarization, machine translation, and text completion.
- Sparse Transformers: Sparse Transformers introduce sparsity patterns into the self-attention mechanism to reduce computation and memory requirements, making transformers more efficient for large-scale models.
- Reformer: The Reformer model addresses memory and efficiency issues in transformers by using reversible layers and locality-sensitive hashing in the attention mechanism. It is well-suited for handling very long sequences.
These transformer types represent just a subset of the wide variety of transformer-based models and architectures used in AI and ML



