What are the Word Embeddings in AI/ML?
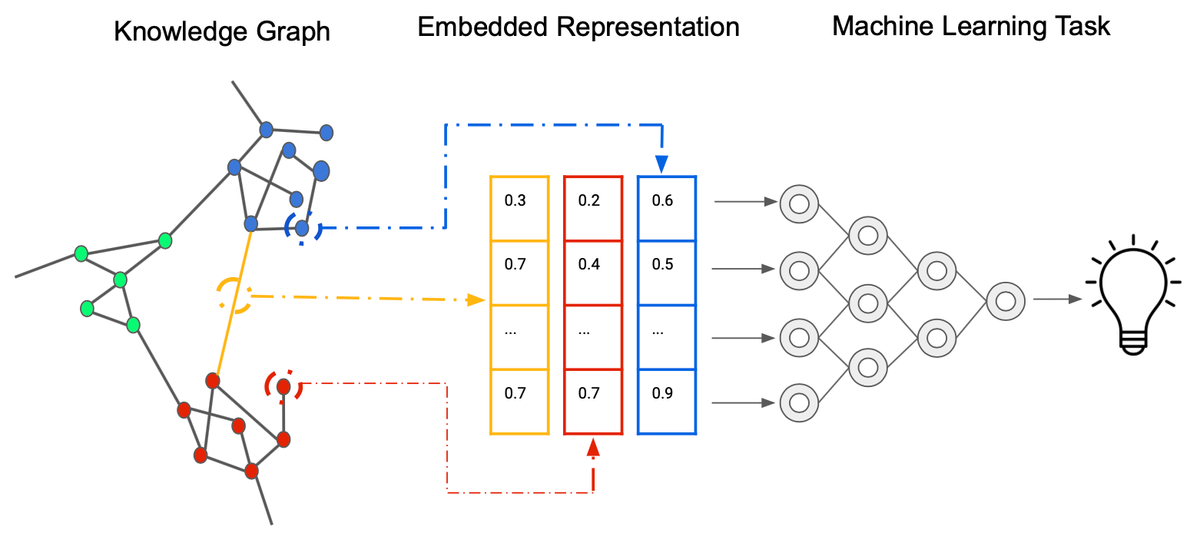
Word embeddings are a type of word representation used in artificial intelligence (AI) and machine learning (ML) to convert words or tokens into numerical vectors. These numerical vectors capture semantic information about words, allowing machines to understand and process human language more effectively. Word embeddings are a crucial component in natural language processing (NLP) tasks, as they enable algorithms to work with textual data in a meaningful way.
Word embeddings are typically trained on a large corpus of text, and the resulting embedding vectors can be used to improve the performance of a variety of natural language processing (NLP) tasks, such as machine translation, text classification, and question answering.
Here are the key points to understand about word embeddings:
- Word Representation: In NLP, words are initially represented as discrete symbols, such as "cat," "dog," or "apple." These symbolic representations are not directly useful for many machine learning algorithms, which require numerical input. Word embeddings bridge this gap by converting words into numerical vectors.
- Continuous Vector Space: Word embeddings represent words in a continuous vector space, where words with similar meanings or contexts have vectors that are close to each other in this space. This allows mathematical operations on word vectors to capture semantic relationships between words.
- Semantic Similarity: Word embeddings capture semantic similarity between words. For example, in a well-trained word embedding space, the vectors for "king" and "queen" would be closer to each other than to unrelated words because of their similar roles in language.
- Pre-trained Word Embeddings: Pre-trained word embeddings are trained on large text corpora and then made available for various NLP tasks. These embeddings are useful because they capture general linguistic knowledge. Examples include Word2Vec, GloVe, and FastText embeddings.
- Contextual Word Embeddings: Some word embeddings take context into account. For instance, ELMo and BERT embeddings consider the surrounding words when generating word representations, allowing for context-aware language understanding.
- Word Embedding Dimensionality: Word embeddings typically have a fixed dimensionality, such as 50, 100, 200, or 300 dimensions. The choice of dimensionality depends on the specific application and resource constraints.
- Word Embedding Training: Word embeddings can be trained from scratch on specific corpora or tasks, or they can be fine-tuned from pre-trained embeddings to adapt them to a particular task or domain.
Some of the benefits of using word embeddings in NLP tasks include:
- Improved performance: Word embeddings can significantly improve the performance of NLP tasks, especially on tasks that require understanding the semantics of words.
- Reduced data requirements: Word embeddings can be used to reduce the amount of data needed to train NLP models. This is because word embeddings can capture the meaning of words from a relatively small amount of data.
- Better generalization: Word embeddings can help NLP models to generalize better to new data. This is because word embeddings capture the relationships between words, which allows models to learn new words and concepts from their context.



