IBM Watsonx.data

Your organization's data to work for AI, ML, and Analytics
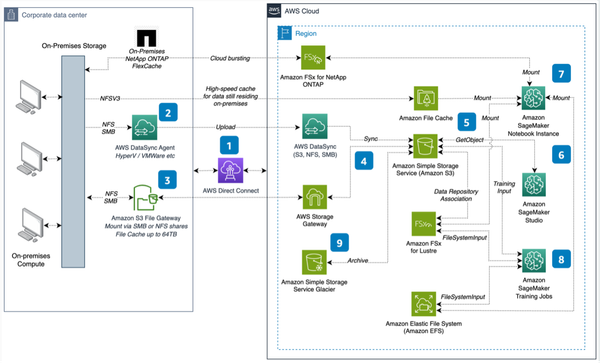
About IBM Watsonx.data
IBM Watsonx.data enables organizations to consolidate and leverage enterprise-wide data for A.I., ML, and Analytics with scalability, performance, governance, and security.
IBM Watsonx.data is a hybrid, open data lakehouse platform designed to unify and manage enterprise data across diverse environments—cloud, on-premises, or hybrid—to support AI and analytics workloads. It combines the scalability of data lakes with the performance of data warehouses, offering a centralized solution for organizations aiming to harness their data for AI-driven insights.
Watsonx.data (a lakehouse platform)
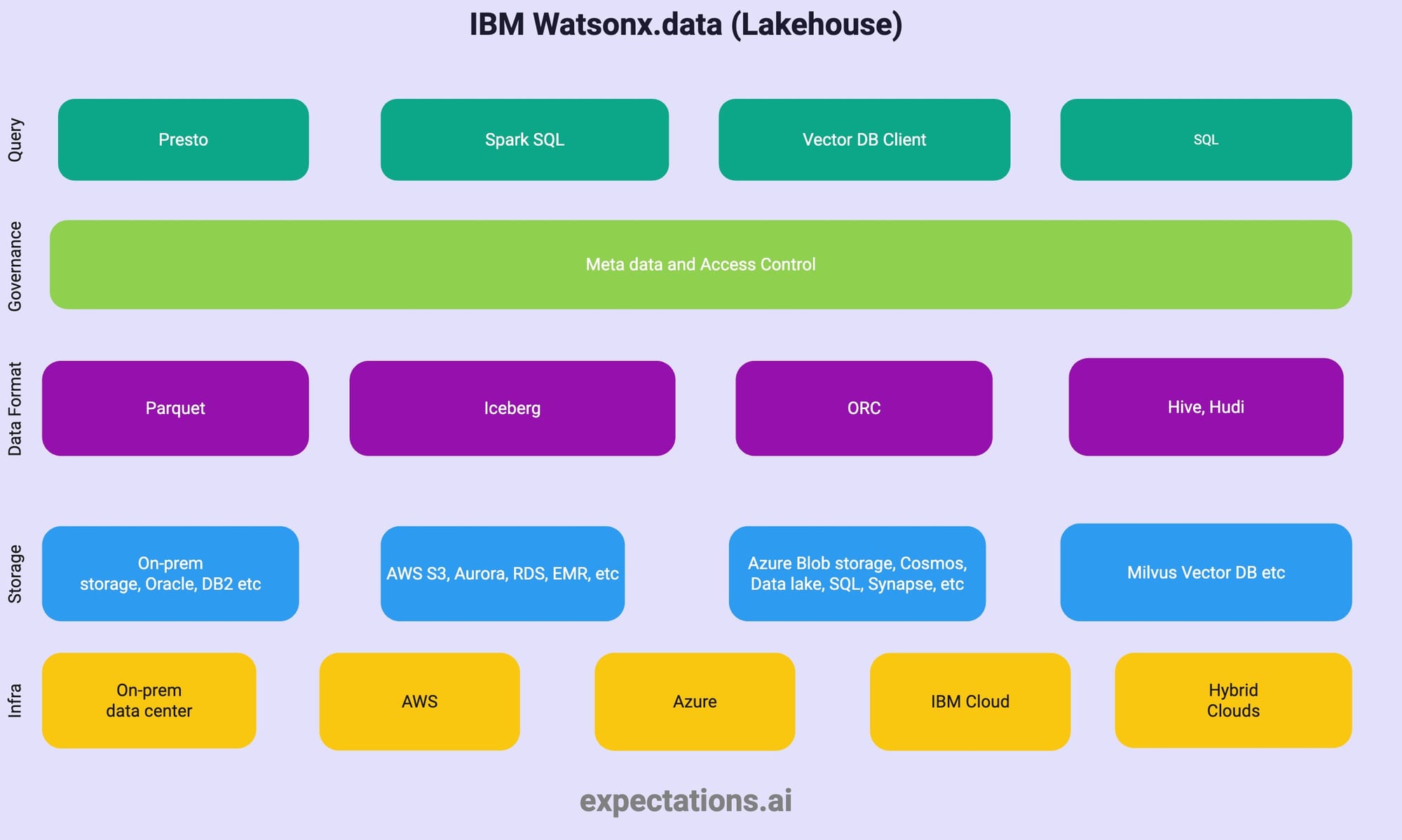
Watsonx.data
IBM Watsonx.data is built on a modern data stack that includes open-source technologies with IBM’s enterprise-grade capabilities.
Infra - Data Lakehouse Foundation
IBM watsonx.data supports a wide range of infrastructure options, giving organizations flexibility to deploy in the
- Cloud (AWS, Azure, IBM)
- Hybrid (On-prem and cloud)
- On-prem (self-managed Red Hat OpenShift) environments
Deployment & Orchestration
- Red Hat OpenShift:
watsonx.data runs on OpenShift for containerized, scalable deployments. - Kubernetes-native Architecture:
Supports multi-cloud and hybrid deployments. - Terraform / Ansible:
For infrastructure as code (IaC) and automated provisioning.
Storage Layers - Data Lakehouse Storage
IBM watsonx.data supports a variety of storage backends to give organizations flexibility depending on their cloud, on-premises, or hybrid architecture. Its open lakehouse architecture is designed to work with object storage, distributed file systems, and data virtualization, enabling seamless access to structured and unstructured data.
Moreover, when paired with Watsonx.data, IBM Storage Scale with GDS accelerates the performance. IBM Storage Scale (formerly known as IBM Spectrum Scale) supports NVIDIA GPUDirect Storage (GDS) to deliver ultra-low latency, high-bandwidth access to data for GPU-accelerated workloads like AI, deep learning, and HPC. NVIDIA GPUDirect Storage is a direct data path that allows data to move from storage to GPU memory (VRAM) without CPU involvement, significantly reducing latency and CPU load.
Supported Object Stores
| Storage Type | Deployment Context |
|---|---|
| IBM Cloud Object Storage | Native for IBM Cloud deployments |
| Amazon S3 | For AWS or hybrid deployments |
| Azure Blob Storage | Supported via integration |
| Google Cloud Storage | Supported via integration |
| S3-compatible storage | MinIO, Dell ECS, Ceph, etc. |
Supported File/Block Storage
| Storage Type | Use Case |
|---|---|
| IBM Storage Scale (GPFS) | High-performance file system on-prem |
| NFS / POSIX-compatible FS | General file storage (e.g., for Spark) |
| Red Hat OpenShift Data Foundation (ODF) | On-prem Kubernetes-native storage |
| Local disk (for dev edition) | Lightweight development/test environments |
Data Virtualization / Federated Storage
Virtualized Sources:
| Source Type | Example Systems |
|---|---|
| Relational databases | PostgreSQL, MySQL, Oracle, Db2 |
| Data warehouses | Snowflake, BigQuery, Redshift |
| NoSQL databases | MongoDB, Cassandra |
| Hadoop HDFS | Hadoop-based data lakes |
| Cloud-native storage APIs | Azure Data Lake, Google BigQuery |
Data format
IBM watsonx.data supports a wide range of open and popular data formats designed for big data, AI/ML workloads, and analytics. These formats enable flexibility, interoperability, and performance optimization across structured, semi-structured, and unstructured data. Supported data formats include
- Tabular / Columnar Formats
- Iceberg, Parquet, ORC (Optimized Row Columnar)
- Row-Based Formats
- CSV, JSON, AVRO
- Vector Data Formats (for AI / RAG workloads)
- FAISS index (via Milvus integration)
- HDF5 or NumPy formats (via Spark or AI tools)
- Other Supported Formats / Sources via Data Virtualization Watsonx.data connect to and query from:
- Relational sources: PostgreSQL, MySQL, Oracle, SQL Server
- NoSQL sources: MongoDB, Cassandra
- Cloud storage formats: Delta Lake, Cloud-native formats from AWS, Azure, GCP
- Data warehouses: Snowflake, BigQuery, Redshift (via federation or data virtualization)
Governance & Security
Metadata & Catalog
- Hive Metastore:
A widely-used metadata catalog service that supports schema definitions and query planning. - Open Metadata Integration:
Can integrate with tools like Apache Atlas, DataHub, or Amundsen for governance and lineage.
Governance & Security
- IBM watsonx.governance (Optional integration):
Provides tools for tracking, auditing, and governing AI models and their associated data. - Data Masking & Row-Level Security:
Built-in data protection mechanisms for compliance (e.g., HIPAA, GDPR). - Role-based Access Control (RBAC) and OAuth/LDAP integration.
Query & Processing Engines
- Presto (Trino):
Distributed SQL engine for interactive analytics across various data sources.- Supports Java and C++ Presto runtimes for different performance needs.
- Apache Spark:
For big data processing, machine learning, and complex batch workloads. - Milvus (Vector Database):
Optimized for retrieval-augmented generation (RAG) and generative AI workloads using vector similarity search.
AI & Machine Learning Integration
- watsonx.ai:
Can connect directly to watsonx.data to train and deploy models using structured/unstructured data. - ML Toolkits:
Integrates with Jupyter Notebooks, Kubeflow, and popular ML frameworks (PyTorch, TensorFlow, scikit-learn).
Interfaces & Integrations
- SQL Interface:
For BI tools like Tableau, Power BI, IBM Cognos, Looker, etc. - REST APIs and Python SDKs:
For developers and data scientists. - Data Virtualization:
Allows access to external sources without data movement.
Key Features of IBM Watsonx.data
- Unified Data Access: Provides a single entry point to access all data, regardless of its location, through a shared metadata layer. This approach reduces data silos and eliminates the need for data duplication
- Multi-Engine Support: Supports multiple query engines, including Presto (Java and C++), Apache Spark, and Milvus, allowing organizations to choose the most suitable engine for their specific workloads
- Open Standards Compatibility: Utilizes open data formats like Apache Iceberg and integrates with Hive Metastore, facilitating interoperability with existing data tools and platforms
- AI and Generative AI Integration: Features built-in support for AI applications, including a vector database (Milvus) for retrieval-augmented generation (RAG) use cases, enhancing the relevance and precision of AI outputs
- Cost Optimization: Enables workload optimization by matching tasks to the appropriate query engine, potentially reducing data warehouse costs
Integration with IBM watsonx Ecosystem
watsonx.data is a component of IBM's broader watsonx suite, which includes:
- watsonx.ai: An AI studio for building and deploying AI models .
- watsonx.governance: Tools for automating AI governance and ensuring compliance.
This integration allows organizations to manage the entire AI lifecycle—from data ingestion and preparation to model deployment and governance—within a cohesive platform.
How It Fits in the IBM Watsonx Suite
| Component | Role |
|---|---|
| watsonx.ai | Train, tune, and deploy foundation models |
| watsonx.data | Manage and query data for AI workloads |
| watsonx.governance | Govern AI use with policy, tracking, explainability |
Together, they offer end-to-end AI lifecycle management — from data to model to deployment to compliance.